本文翻译自 StreamNative 博客《What the FLiP is the FLiP Stack?》
- 原文链接:https://streamnative.io/blog/engineering/2022-04-14-what-the-flip-is-the-flip-stack/
- 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/KoigahiZ2sTG-GhD2fG0Fw
In this article on the FLiP Stack, we will explain how to build a real-time event driven application using the latest open source frameworks. We will walk through building a Python IoT application utilizing Apache Pulsar, Apache Flink, Apache Spark, and Apache NiFi. You will see how quickly we can build applications for a plethora of use cases. The easy, fast, scalable way: The FLiP Way.
本文将介绍 FLiP 技术栈,我们将解释如何使用最新的开源框架构建实时事件驱动应用程序,并介绍如何通过 Apache Pulsar、Apache Flink、Apache Spark 和 Apache NiFi 构建一个 Python IoT 应用。得益于 FLiP 的简单、快速、可扩展的特性,使用 FLiP 可以快速地为各种场景构建应用程序。
The FLiP Stack is a number of open source technologies that work well together. FLiP is a best practice pattern for building a variety of streaming data applications. The projects in the stack are dictated by the needs of that use case; the available technologies in the builder’s current stack; and the desired end results. As we shall see, there are several variations of the FLiP stack built upon the base of Apache Flink and Apache Pulsar.
FLiP 技术栈由许多可协同工作的开源技术组成,是构建各种流数据应用程序的最佳实践模式。FLiP 技术栈包含哪些项目并不是固定的,而是由特定场景的需求、团队当前掌握的技术栈、以及期望的最终结果决定。建立在 Apache Flink 和 Apache Pulsar 基础上的 FLiP 技术栈有很多变体。
For some use cases like log analytics, you will need a nice dashboard for visualizing, aggregating, and querying your log data. For that one you would most likely want something like FLiPEN, as an enhancement to the ELK Stack. As you can tell, FLiP+ is a moving list of acronyms for open source projects that are commonly used together.
例如对于日志分析这种场景,通常需要清晰直观的仪表板来可视化、聚合并查询日志数据。对于这种场景,你可能需要像 FLiPEN 这样的技术,作为对 ELK 技术栈 的增强。由此可以看出,FLiP+ 是一个可变的缩写,表示多种配合使用的开源项目。
Common Use Cases - 常见场景
With so many variations of the FLiP stack, it might be difficult to figure out which one is right for you. Therefore, we have provided some general guidelines for selecting the proper FLiP+ stack to use based on your use case. We already mentioned Log Analytics, which is a common use case. There are many more, driven usually by data sources and data sinks.
由于 FLiP 技术栈的变体非常多,所以可能很难确定哪一种适合你的场景。因此,我们提供了一些通用指南,你可以根据不同的场景选择合适的 FLiP+ 技术栈。上文提到的日志分析是一种常用场景,当然还有其他更多的场景,通常由数据 source 和 sink 驱动。
| 场景(数据) | 技术栈 | 演示 |
|---|---|---|
| 点击流 | FLiP-C | https://github.com/tspannhw/FLiP-Stream2Clickhouse |
| IoT | FLiP-I | https://github.com/tspannhw/FLiP-InfluxDB |
| CDC | FLiPS | https://github.com/tspannhw/FLiPS-SparkOnPulsar |
| 统一消息 | FLiP* | https://github.com/tspannhw/FLiPN-Demos |
| Lakehouse,云数据湖 | FLiP | https://github.com/tspannhw/FLiP-CloudIngest |
| 移动应用 | FLiP-M | https://github.com/tspannhw/FLiP-Mobile |
| 微服务 | FLiP | https://streamnative.io/blog/engineering/2021-12-14-developing-event-driven-microservices-with-apache-pulsar/ |
| SQL on Topics | FLiPiT | https://github.com/tspannhw/FLiP-Into-Trino |
| 边缘 AI | FLip-EdgeAI | https://github.com/tspannhw/FLiP-EdgeAI |
| ETL | FLiPS | https://github.com/tspannhw/FLiPS-SparkOnPulsar |
| 搜索 | FLiPEN | https://github.com/tspannhw/FLiP-Elastic |
| Python 应用 | FLiP-Py | https://github.com/tspannhw/FLiP-Py-Pi-GasThermal |
Flink-Pulsar Integration - Flink-Pulsar 集成
A critical component of the FLiP stack is utilizing Apache Flink as a stream processing engine against Apache Pulsar data. This is enabled by the Pulsar-Flink Connector that enables developers to build Flink applications natively and stream in events from Pulsar at scale as they happen. This allows for use cases such as streaming ELT and continuous SQL on joined topic streams. SQL is the language of business that can drive event-driven, real-time applications by writing simple SQL queries against Pulsar streams with Flink SQL, including aggregation and joins.
FLiP 技术栈的一个关键组件是利用 Apache Flink 作为流式处理引擎来处理 Apache Pulsar 数据。这是基于 Pulsar-Flink 连接器实现的,开发人员可以构建原生的 Flink 应用,并在事件发生时从 Pulsar 大规模地流式传输事件,适用于流式 ELT 以及在主题流上持续执行 SQL 等场景。SQL 是一种业务语言,可以通过使用 Flink SQL 编写针对 Pulsar 流的简单 SQL 查询(包括聚合和连接)来实现事件驱动的实时应用程序。
The connector builds an elastic data processing platform enabled by Apache Pulsar and Apache Flink that is seamlessly integrated to allow full read and write access to all Pulsar messages at any scale. As a citizen data engineer or analyst you can focus on building business logic without concern about where the data is coming from or how it is stored.Check out the resources below to learn more about this connector:
Pulsar-Flink 连接器构建了一个弹性数据处理平台,通过无缝集成 Apache Pulsar 和 Apache Flink 允许以任何规模对 Pulsar 消息进行完全读写访问。作为数据工程师或数据分析师,你可以专注于业务逻辑,而无需担心数据来源以及存储。可以通过如下资源学习更多关于 Pulsar-Flink 连接器的知识:
- [Blog] What’s New in the Pulsar Flink Connector 2.7.0 [博客] 打造全新批流融合:详解 Apache Flink 1.14.0 发布的 Pulsar Flink Connector
- [Blog] Flink SQL on StreamNative Cloud [博客] 批流一体上云:StreamNative Cloud 支持 Flink SQL
- [Code] Streaming Analytics with Apache Pulsar and Apache Flink SQL [代码] 使用 Apache Pulsar 和 Apache Flink SQL 进行流式分析
NiFi-Pulsar Integration - NiFi-Pulsar 集成
If you have been following our blog, you have seen the recent formal announcement of the Apache Pulsar processor for Apache NiFi release. We now have an official way to consume and produce messages from any Pulsar topic with the low code streaming tool that is Apache NiFi.
近期,StreamNative 与 Cloudera 宣布推出 Apache Pulsar + Apache NiFi 联合解决方案。现在我们官方支持利用 Apache NiFi 这种低代码流式工具从任何 Pulsar 主题中消费和生产消息。
This integration allows us to build a real-time data processing and analytics platform for all types of rich data pipelines. This is the keystone connector for the democratization of streaming application development.
利用 NiFi-Pulsar 集成,我们可以为任何数据管道构建实时数据处理和分析平台。这是流式应用程序开发平民化的关键连接器。
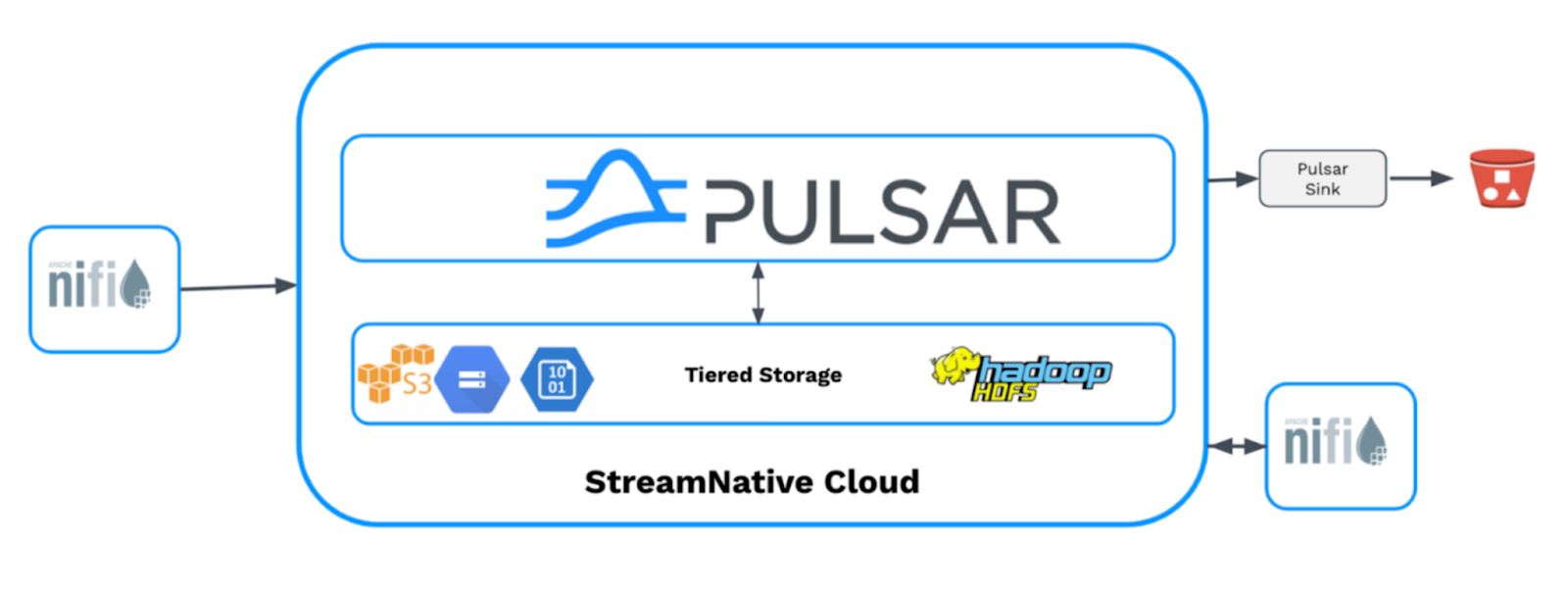
若要了解更多信息,可以阅读如下文章:
[Blog] Cloudera and StreamNative Announce the Integration of Apache NiFi and Apache Pulsar [博客] StreamNative 与 Cloudera 宣布推出 Apache Pulsar + Apache NiFi 联合解决方案
[Blog] Producing and Consuming Pulsar messages with Apache NiFi [博客] Producing and Consuming Pulsar messages with Apache NiFi
[Datanami Article] Code for Pulsar, NiFi Tie-Up Now Open Source [Datanami 文章] Code for Pulsar, NiFi Tie-Up Now Open Source
[Resources] Pulsar and NiFi Integration Resources [资源] Pulsar and NiFi Integration Resources
An Example FLiP Stack Application - FLiP 技术栈示例
Now that you have seen the combinations, use cases, and the basic integration, we can walk through an example FLiP Stack application. In this example, we will be ingesting sensor data from a device running a Python Pulsar application.
上文介绍了 FLiP 的技术组合、使用场景以及基本集成,现在我们来看一个 FLiP 技术栈应用的示例。在此示例中,我们从一个运行 Python Pulsar 程序的设备中采集传感数据。
 Demo Edge Hardware Specifications - 演示使用的边缘端硬件规格
Demo Edge Hardware Specifications - 演示使用的边缘端硬件规格
2GB 内存的 Raspberry Pi 4
Pimoroni BreakoutGarden Hat
Sensiron SGP30 TVOC 及 eCO2 传感器
- TVOC 传感器用于 0-60,000 ppb(十亿分之几)
- CO2 传感器用于 400-60,000 ppm(百万分之几)

Demo Edge Software Specification - 演示所用的边缘端软件规格
- Apache Pulsar C++ 及 Python 客户端
- Pimoroni SGP30 Python 库
Streaming Server - 流式服务器
- HP ProLiant DL360 G7 1U RackMount 64 位服务器
- Ubuntu 18.04.6 LTS
- 72GB PC3 RAM
- X5677 Xeon 3.46GHz 24 核 CPU
- 4×900GB 10K SAS SFF HDD
- Apache Pulsar 2.9.1
- Apache Spark 3.2.0
- Scala 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_302)
- Apache Flink 1.13.2
- MongoDB
NiFi/AI Server - NiFi/AI 服务器
- NVIDIA® Jetson Xavier™ NX Developer Kit
- AI Perf: 21 TOPS
- GPU: 48 Tensor Core 的 384 核 NVIDIA Volta™ GPU
- CPU:6 核 NVIDIA Carmel ARM®v8.2 64 位 CPU 6 MB L2 + 4 MB L3
- 内存:8 GB 128 位 LPDDR4x 59.7GB/s
- Ubuntu 18.04.5 LTS (GNU/Linux 4.9.201-tegra aarch64)
- Apache NiFi 1.15.3
- Apache NiFi Registry 1.15.3
- Apache NiFi Toolkit 1.15.3
- Pulsar 处理器
- OpenJDK 8 and 11
- Jetson Inference GoogleNet
- Python 3
Building the Air Quality Sensors Application with FLiPN-Py - 使用 FLiPN-Py 构建空气质量传感器程序
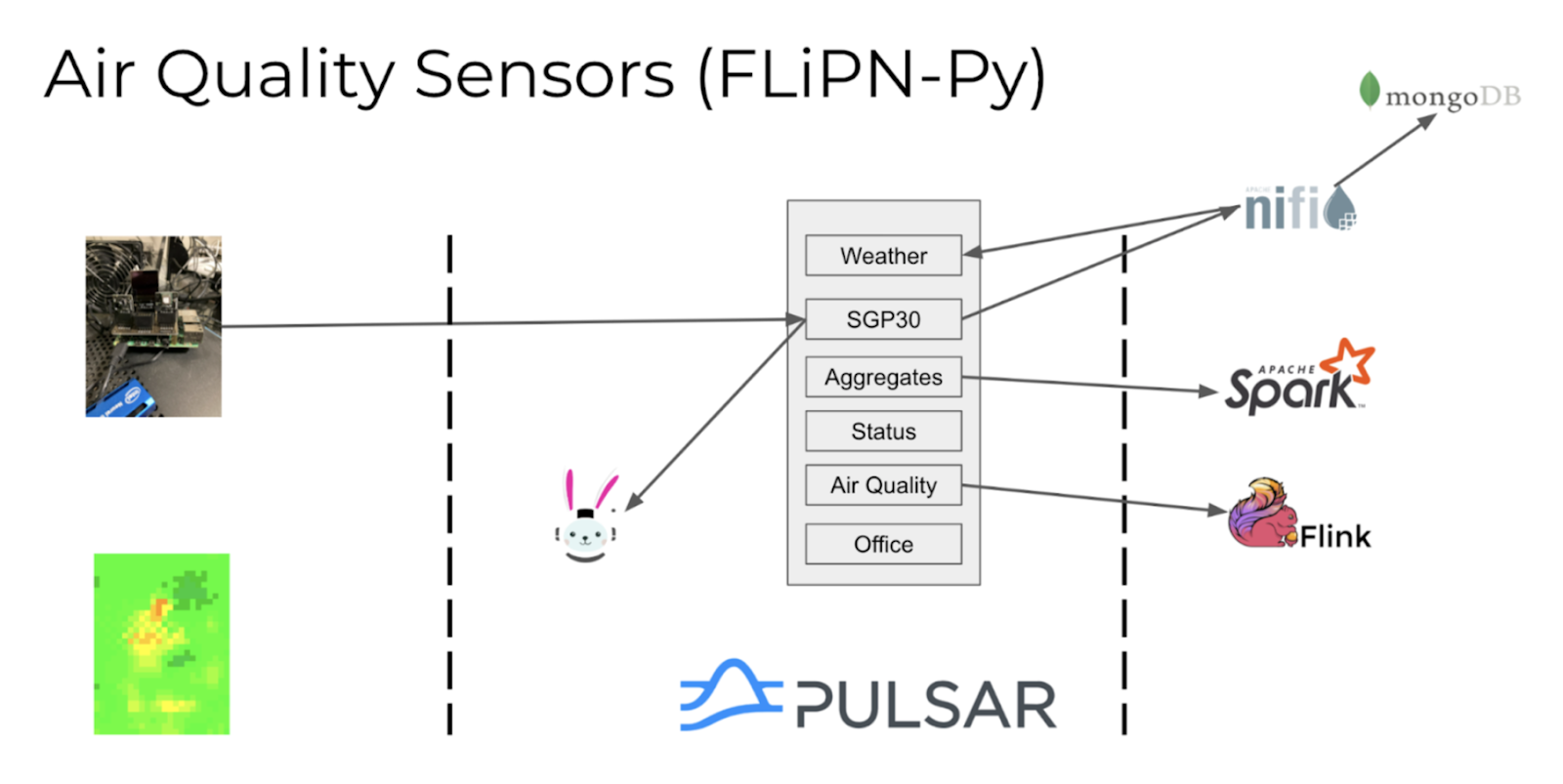
在这个示例程序中,我们希望持续监测办公室的空气质量,然后将大量数据交给数据科学家进行预测。一旦该模型完成,我们会将其添加到 Puslar Function 中进行实时异常检测,发送告警给办公室人员。我们还需要仪表盘来监控趋势、进行聚合和高级分析。
Once the initial prototype proves itself, we will deploy it to all the remote offices for monitoring internal air quality. For future enhancements, we will ingest outside air quality data as well local weather conditions.
一旦初始的原型证明可用,我们将部署到所有远程办公室以监测内部空气质量。未来我们将持续改进,采集外部空气质量数据以及当地天气状况。
On our edge devices, we will perform the following three steps to collect the sensor readings, format the data into the desired schema, and forward the records to Pulsar.
我们的客户端设备执行如下三个步骤来收集传感器读数,将数据格式化为期望的 schema,并将记录发送到 Pulsar。
Edge Step 1: Collect Sensor Readings - 边缘端第一步:收集传感器读数
result = sgp30.get_air_quality()
Edge Step 2: Format Data According to Schema - 边缘端第二步:根据 Schema 格式化数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Edge Step 3: Produce Record to Pulsar Topic - 边缘端第三步:生产记录到 Pulsar 主题
1
| |
Now that we have built the edge-to-pulsar ingestion pipeline, let’s do something interesting with the sensor data that we have published to Pulsar.
现在我们构建了从边缘设备到 Pulsar 的数据采集管道,接下来我们对发布到 Pulsar 的传感器数据做一些有意思的处理。
Cloud Step 1: Spark ETL to Parquet Files - 云端第一步:通过 Spark ETL 转成 Parquet 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Cloud Step 2: Continuous SQL Analytics with Flink SQL - 云端第二步:使用 Flink SQL 进行持续 SQL 分析
1 2 3 | |
Cloud Step 3: SQL Analytics with Pulsar SQL - 云端第三步:使用 Pulsar SQL 进行 SQL 分析
1
| |
Cloud Step 4: NiFi Filter, Route, Transform and Store to MongoDB - 云端第四步:NiFi 过滤、路由、转换并存储到 MongoDB

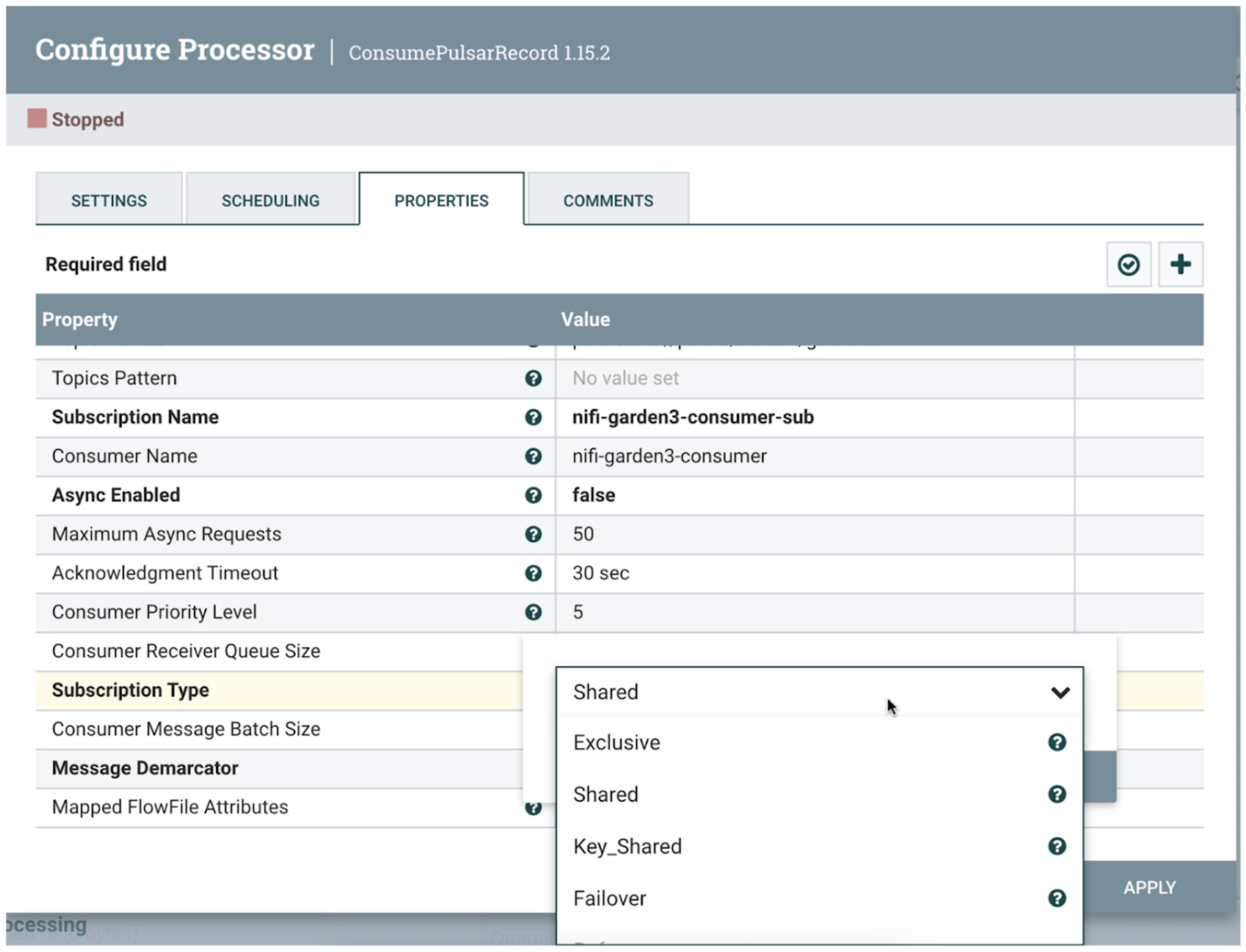
We could have used a Pulsar Function and Pulsar IO Sink for MongoDB instead, but you may want to do other data enrichment with Apache NiFi without coding.
我们本可以为 MongoDB 使用 Pulsar Function 和 Pulsar IO Sink,但使用 Apache NiFi 无需编码就能完成数据丰富。
Cloud Step 5: Validate MongoDB Data - 云端第五步:验证 MongoDB 数据
1 2 | |
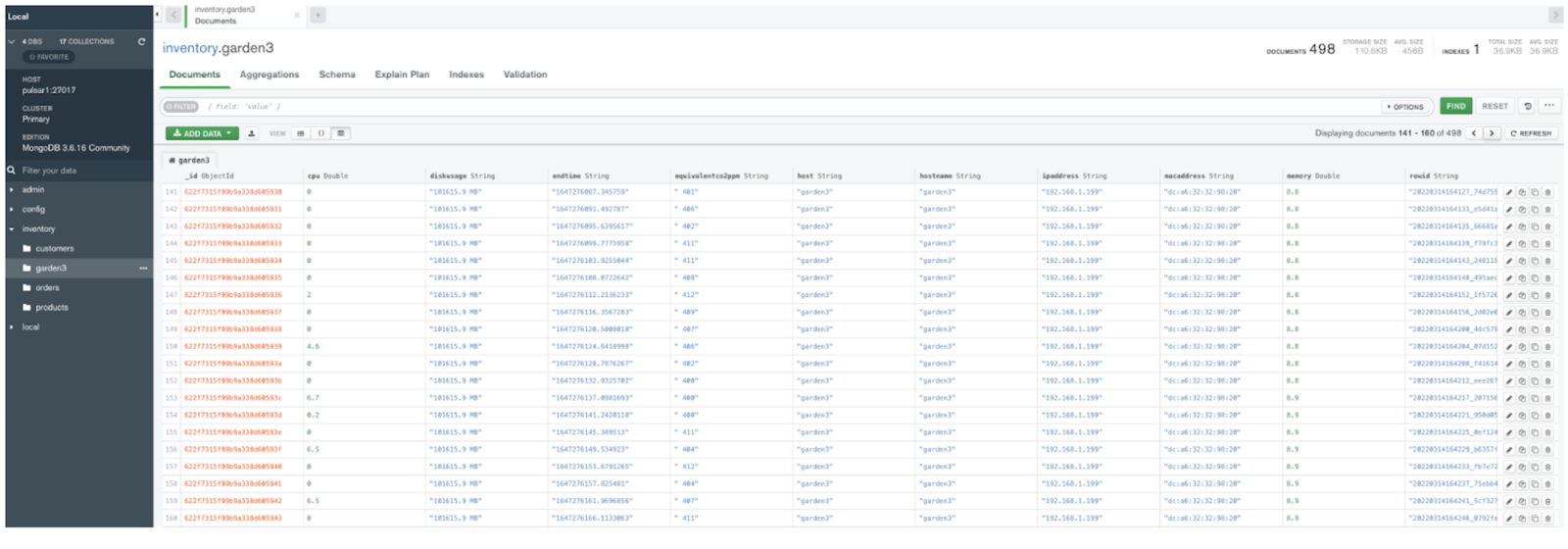

Example Row - 示例数据
1
| |
Example HTML Data Display Utilizing Web Sockets - 使用 Web Socket 的 HTML 示例数据展示
Watch the Demo观看演示视频
(https://streamnative.io/blog/engineering/2022-04-14-what-the-flip-is-the-flip-stack/)

Conclusion - 结论
In this blog, we explained how to build real-time event driven applications utilizing the latest open source frameworks together as FLiP Stack applications. So now you know what we are talking about when we say “FLiPN Stack”. By using the latest and greatest open source Apache streaming and big data projects together, we can build applications faster, easier, and with known scalable results.
本文介绍了如何利用最新的开源框架组成 FLiP 技术栈,来构建实时事件驱动应用程序。通过使用最新的优秀的开源 Apache 流处理和大数据项目,我们可以更快、更轻松、更可扩展地构建应用程序。
Join us in building scalable applications today with Pulsar and its awesome friends. Start with data, route it through Pulsar, transform it to meet your analytic needs, and stream it to every corner of your enterprise. Dashboards, live reports, applications, and machine learning analytics driven by fast data at scale built by citizen data engineers in hours, not months. Let’s get these FLiPN applications built now.
欢迎大家使用 Pulsar 及其他上下游生态中出色的工具来构建可扩展的应用程序。从数据开始,通过 Pulsar 进行路由,对其进行转换以满足分析需求,并将其流式传输到企业的每个角落。无需数月的时间,数据工程师即可在数小时内构建出大规模快速数据驱动的仪表板、实时报告、应用程序以及机器学习分析数据。现在就开始构建这些 FLiPN 应用程序吧。