本文翻译自 StreamNative 博客《Achieving Broker Load Balancing with Apache Pulsar》 - 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/p9nWE_cyzYENNxEzXGXcew
In this blog, we talk about the importance of load balancing in distributed computing systems and provide a deep dive on how Pulsar handles broker load balancing. First, we’ll cover Pulsar’s topic-bundle grouping, bundle-broker ownership, and load data models. Then, we’ll walk through Pulsar’s load balancing logic with sequence diagrams that demonstrate bundle assignment, split, and shedding. By the end of this blog, you’ll understand how Pulsar dynamically balances brokers.
本文将探讨负载均衡在分布式计算系统中的重要性,并深入分析 Pulsar 处理 Broker 负载均衡的方式。首先我们介绍 Pulsar 中的 Topic-Bundle 分组、Bundle-Broker 归属关系以及负载数据模型。然后讲解 Pulsar 的负载均衡逻辑,通过时序图来展示 Bundle 的分配、拆分和缩减过程。通过本文,你将了解 Pulsar Broker 是如何做到动态均衡的。
Before we dive into the details of Pulsar’s broker load balancing, we’ll briefly discuss the challenges of distributed computing, and specifically, systems with monolithic architectures.
在深入探讨 Pulsar Broker 负载均衡的细节之前,我们先简要讨论分布式计算的挑战,特别是单体架构系统的挑战。
The challenges of load balancing in distributed streaming - 分布式流系统中负载均衡的挑战
A key challenge of distributed computing is load balancing. Distributed systems need to evenly distribute message loads among servers to avoid overloaded servers that can malfunction and harm the performance of the cluster. Topics are naturally a good choice to partition messages because messages under the same topic (or topic partition) can be grouped and served by a single logical server. In most distributed streaming systems, including Pulsar, topics or groups of topics are considered a load-balance entity, where the systems need to evenly distribute the message load among the servers.
负载均衡是分布式计算中的一大关键挑战。分布式系统需要在服务器之间平均分配消息负载,以避免出现服务器过载,从而导致故障并损害集群性能。一个自然而然的合理选择是根据主题来对消息进行拆分,因为同一主题(或主题分区)下的消息可以组织到一起并分配给单个逻辑服务器处理。包括 Pulsar 在内的多数分布式流系统将主题或一组主题视为负载均衡的实体,系统需要在服务器之间平均分配主题或一组主题的消息负载。
Topic load balancing can be challenging when topic loads are unpredictable. When there is a load increase in certain topics, these topics must offload directly or repartition to redistribute the load to other machines. Alternatively, when machines receive low traffic or become idle, the cluster needs to rebalance to avoid wasting server resources.
当主题负载不可预测时,如何做好主题负载均衡可能会形成挑战。当某些主题的负载增加时,这些主题必须直接卸载或者重新分区,以便将负载重新分配到其他机器。另一种情况是,某些机器流量非常低,甚至空闲,集群需要重平衡来避免服务器资源浪费。
Dynamic rebalancing can be difficult in monolithic architectures, where messages are both served and persisted in the same stateful server. In monolithic streaming systems, rebalancing often involves copying messages from one server to another. Admins must carefully compute the initial topic distribution to avoid future rebalancing as much as possible. In many cases, they need careful orchestration to execute topic rebalancing.
动态重平衡在单体架构中可能会很困难,因为消息在同一个有状态的服务器中处理以及持久化。在单体流式系统中,重平衡通常涉及将消息从一台服务器复制到另一台服务器。管理员必须仔细计算初始主题分布,尽可能避免将来发生重平衡。在许多情况下,管理员需要仔细编排才能执行主题重平衡操作。
An overview of load balancing in Pulsar - Pulsar 负载均衡概览
By contrast, Apache Pulsar is equipped with automatic broker load balancing that requires no admin intervention. Pulsar’s architecture separates storage and compute, making the broker-topic assignment more flexible. Pulsar brokers persist messages in the storage servers, which removes the need for Pulsar to copy messages from one broker to another when rebalancing topics among brokers. In this scenario, the new broker simply looks up the metadata store to point to the correct storage servers where the topic messages are located.
相比之下,Apache Pulsar 则实现了 Broker 的动态负载均衡,无需管理员手工干预。Pulsar 从架构上分离了存储层和计算层,可以更加灵活地分配 Broker 与主题的映射关系。Pulsar Broker 将消息持久化保存到存储服务器,当在 Broker 之间重平衡主题时,无需将消息从一个 Broker 复制到另一个 Broker。在这种情况下,新加入的 Broker 只需要查找 Metadata Store 并指向主题消息所在的正确存储服务器即可。
Let’s briefly talk about the Pulsar storage architecture to have the complete Pulsar’s scaling context here. On the storage side, topic messages are segmented into Ledgers, and these Ledgers are distributed to multiple BookKeeper servers, known as bookies. Pulsar horizontally scales its bookies to distribute as many Ledger (Segment) entities as possible.
这里简要讨论一下 Pulsar 的存储架构,以便全面地了解 Pulsar 的扩展能力。在存储层,主题消息被分割成多个 Ledger,这些 Ledger 分布到多个 BookKeeper 服务器,即 Bookie。Pulsar 通过水平扩展 Bookie,即可存储尽可能多的 Ledger(Segment)条目。
For a high write load, if all bookies are full, you could add more bookies, and the new message entries (new ledgers) will be placed on the new bookies. With this segmentation, during the storage scaling, Pulsar does not involve recopying old messages from bookies. For a high read load, because Pulsar caches messages in the brokers' memory, the read load on the bookies significantly offloads to the brokers, which are load-balanced. You can read more about Pulsar Storage architecture and scaling information in the blog post Comparing Pulsar and Kafka.
对于高写入负载,如果所有 Bookie 都已满,只需增加更多的 Bookie,新的消息条目(即新的 Ledger)即可存储到这些新的 Bookie 上。通过这种分段设计,在存储扩展期间 Pulsar 无需从 Bookie 中重新复制旧消息。对于高读取负载,Pulsar 将消息缓存在 Broker 内存中,所以 Bookie 的读负载会显著卸载到 Broker 上,而 Broker 是负载均衡的。你可以在这篇关于对比 Pulsar 与 Kafka 的博文中了解更多关于 Pulsar 存储架构以及扩展能力的信息。
Topics are assigned to brokers at the bundle level - 在 Bundle 级别分配主题到 Broker
From the client perspective, Pulsar topics are the basic units in which clients publish and consume messages. On the broker side, a single broker will serve all the messages for a topic from all clients. A topic can be partitioned, and partitions will be distributed to multiple brokers. You could regard a topic partition as a topic and a partitioned topic as a group of topics.
从客户端的角度来看,Pulsar 主题是客户端发布和消费消息的基本单元。在 Broker 端,单个 Broker 处理所有客户端对某个主题的所有消息请求。主题可以被分区,而分区可以分布在多个 Broker 上。你可以将主题分区视为一个主题,而将被分区的主题视为一组主题。
Because it would be inefficient for each broker to serve only one topic, brokers need to serve multiple topics simultaneously. For this multi-topic ownership, the concept of a bundle was introduced in Pulsar to represent a middle-layer group.
由于每个 Broker 只处理一个主题效率较低,所以一般 Broker 需要同时处理多个主题。对于这种多主题归属关系,Pulsar 引入了 Bundle 的概念来作为一种中间层组。
Related topics are logically grouped into a namespace, which is the administrative unit. For instance, you can set configuration policies that apply to all the topics in a namespace. Internally, a namespace is divided into shards, aka the bundles. Each of these bundles becomes an assignment unit.
在 Pulsar 中,相关的主题可以在逻辑上归到一个命名空间中。命名空间是一个管理单元,例如可以设置一套配置策略,应用到命名空间中的所有主题上。命名空间内部被分成多个分片,即 Bundle,每个 Bundle 是负载均衡的分配单元。
Pulsar uses bundles to shard topics, which will help reduce the amount of information to track. For example, Pulsar LoadManger aggregates topic load statistics, such as message rates at the bundle layer, which helps reduce the number of load samples to monitor. Also, Pulsar needs to track which broker currently serves a particular topic. With bundles, Pulsar can reduce the space needed for this ownership mapping.
Pulsar 使用 Bundle 来对主题进行分片,这有助于减少要跟踪的信息量。例如,Pulsar LoadManager 聚合了主题负载统计信息,比如 Bundle 层的消息速率,这有助于减少要监控的负载样本数量。此外,Pulsar 需要跟踪当前是哪个 Broker 服务于特定主题。得益于 Bundle,Pulsar 可以减少维护这种归属关系所需的存储空间。
Pulsar uses a hash to map topics to bundles. Here’s an example of two bundles in a namespace.
Pulsar 使用哈希算法将主题映射到 Bundle。如下是一个命名空间包含两个 Bundle 的示例。
1 2 3 | |
Pulsar computes the hashcode given topic name by Long hashcode = hash(topicName). Let’s say hash(“my-topic”) = 0x0000000F. Then Pulsar could do a binary search by NamespaceBundle getBundle(hashCode) to which bundle the topic belongs given the bundle key ranges. In this example, “Bundle1” is the one to which “my-topic” belongs.
Pulsar 通过 Long hashcode = hash(topicName) 来计算给定主题名的哈希码。假设 hash(“my-topic”) = 0x0000000F,在已知 Bundle Key 范围的情况下,Pulsar 可通过 NamespaceBundle getBundle(hashCode) 进行二分搜索,找到主题所属的 Bundle。在此示例中,“my-topic” 属于 “Bundle1”。
Brokers dynamically own bundles on demand - Bundle 按需动态归属到 Broker
One of the advantages of Pulsar’s compute (brokers) and storage (bookies) separation is that Pulsar brokers can be stateless and horizontally scalable with dynamic bundle ownership. When brokers are overloaded, more brokers can be easily added to a cluster and redistribute bundle ownerships.
Pulsar 计算层(Broker)和存储层(Bookie)分离的一大优势是 Pulsar Broker 是无状态的,基于动态 Bundle 归属可以实现良好的水平扩展性。当 Broker 过载后,可以轻松地将更多 Broker 加入集群并重新分配 Bundle 归属关系。
To discover the current bundle-broker ownership in a given topic, Pulsar uses a server-side discovery mechanism that redirects clients to the owner brokers’ URLs. This discovery logic requires:
- Bundle key ranges for a given namespace, in order to map a topic to a bundle.
- Bundle-Broker ownership mapping to direct the client to the current owner or to trigger a new ownership acquisition in case there is no broker assigned.
Pulsar 使用服务端发现机制来发现给定主题当前的 Bundle-Broker 归属关系,将客户端重定向到 Owner Broker 的 URL。这种发现逻辑需要知道:
- 给定命名空间的 Bundle Key 范围,以便将主题映射到 Bundle。
- Bundle-Broker 归属关系,以便将客户端定向到当前 Owner;如果尚未分配 Broker,则触发新一轮归属关系分配。
Pulsar stores bundle ranges and ownership mapping in the metadata store, such as ZooKeeper or etcd, and the information is also cached by each broker.
Pulsar 将 Bundle 范围和归属关系存储在 Metadata Store 中,例如 ZooKeeper 或 etcd,这些信息也会缓存在每个 Broker 中。
Load data model - 负载数据模型
Collecting up-to-date load information from brokers is crucial to load balancing decisions. Pulsar constantly updates the following load data in the memory cache and metadata store and replicates it to the leader broker. Based on this load data, the leader broker runs topic-broker assignment, bundle split, and unload logic:
- Bundle Load Data contains bundle-specific load information, such as bundle-specific msg in/out rates.
- Broker Load Data contains broker-specific load information, such as CPU, memory, and network throughput in/out rates.
负载均衡决策中至关重要的一点是从 Broker 端收集最新的负载信息。Pulsar 不断将以下负载数据更新到内存缓存和 Metadata Store 中,并将其复制到 Leader Broker。基于这些负载数据,Leader Broker 执行 Topic-Broker 分配、Bundle 拆分以及卸载逻辑:
- Bundle 负载数据(Bundle Load Data),包含 Bundle 相关的负载信息,例如 Bundle 的消息输入/输出速率。
- Broker 负载数据(Broker Load Data),包含 Broker 相关的负载信息,例如 CPU、内存以及网络吞吐量输入/输出速率。
Load balance sequence - 负载均衡时序图
In this section, we’ll walk through load balancing logic with sequence diagrams:
- Assigning topics to brokers dynamically (Read the complete documentation.)
- Splitting overloaded bundles (Read the complete documentation.)Shedding bundles from overloaded brokers (Read the complete documentation.)
本节将通过时序图来展示负载均衡逻辑: - 将主题动态分配到 Broker(阅读完整文档)。 - 拆分过载的 Bundle(阅读完整文档)。 - 从过载的 Broker 中卸载 Bundle(阅读完整文档)。
Assigning topics to brokers dynamically - 将主题动态分配到 Broker

假设某客户端想要读写主题,现在试图连接到一个 Broker。该客户端先会连接到一个随机的 Broker,该 Broker 首先根据主题的哈希码以及命名空间的 Bundle 范围搜索匹配的 Bundle。然后,该 Broker 会查询 Metadata Store,检查所匹配的 Bundle 是否属于某 Broker。如果已经归属,该 Broker 会将客户端重定向到 Owner URL。否则,会将客户端重定向到 Leader 以进行 Broker 分配。Broker 分配逻辑如下:Leader 首先基于配置好的规则过滤出可用的 Broker 列表,然后随机选择一个负载最少的 Broker 分配给 Bundle(如下文第一步所示),并返回该 Broker 的 URL;Leader 将客户端重定向到该 URL,客户端即可连接到分配的 Broker。新的 Broker-Bundle 归属关系会在 Metadata Store 中创建一个临时锁,一旦 Owner 不可用之后该锁会自动释放。
Section 1: Selecting a broker - 第一步:选定 Broker
This step selects a broker from the filtered broker list. As a tie-breaker strategy, it uses ModularLoadManagerStrategy (LeastLongTermMessageRate by default). LeastLongTermMessageRate computes brokers’ load scores and randomly selects one among the minimal scores by the following logic:
- If the maximum local usage of CPU, memory, and network is bigger than the
LoadBalancerBrokerOverloadedThresholdPercentage(default 85%), thenscore=INF. - Otherwise,
score = longTermMsgInrate andlongTermMsgOutrate.
这一步从已过滤的可用 Broker 列表中选定一个 Broker,使用 ModularLoadManagerStrategy(默认为 LeastLongTermMessageRate)。LeastLongTermMessageRate 策略计算 Broker 的负载分数,并从分数最小的 Broker 中随机选择一个,计分规则如下:
- 如果 CPU、内存和网络的最大本地使用率大于
LoadBalancerBrokerOverloadedThresholdPercentage(默认 85%),则设置score=INF。 - 否则设置分数为
longTermMsgIn消息输入速率加上longTermMsgOut消息输出速率。
Splitting overloaded bundles## 拆分过载的 Bundle
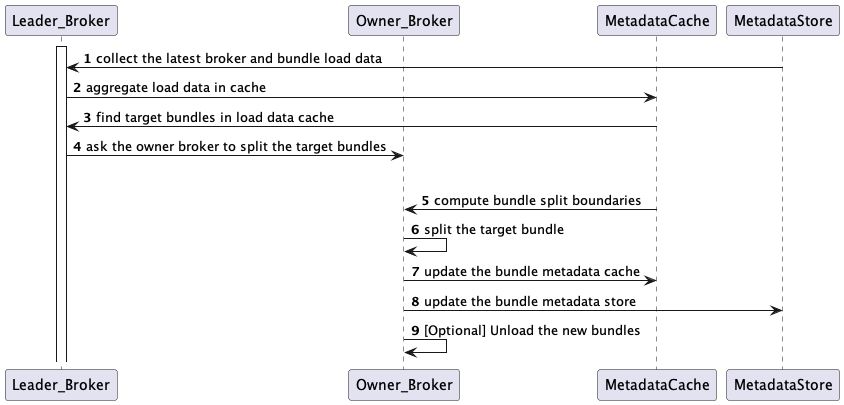
With the bundle load data, the leader broker identifies which bundles are overloaded beyond the threshold as shown in Section 2 below and asks the owner broker to split them. For the split, the owner broker first computes split positions, as shown in Section 3 below, and repartition the target bundles at them, as shown in Section 4 below. After the split, the owner broker updates the bundle ownerships and ranges in the metadata store. The newly split bundles can be automatically unloaded from the owner broker, configurable by the LoadBalancerAutoUnloadSplitBundlesEnabled flag.
Leader Broker 根据 Bundle 负载数据判断哪些 Bundle 的负载超过阈值(见第二步),并要求 Owner Broker 进行 Bundle 拆分。具体的拆分逻辑如下:Owner Broker 首先计算拆分位置(见第三步),然后据此重新拆分目标 Bundle(见第四步);完成拆分之后,Owner Broker 将最新的 Bundle 归属关系和范围更新到 Metadata Store 中。如果启用了 LoadBalancerAutoUnloadSplitBundlesEnabled,新拆分的 Bundle 可以从 Owner Broker 中自动卸载。
Section 2: Finding target bundles - 第二步:查找目标 Bundle
If the auto bundle split is enabled by loadBalancerAutoBundleSplitEnabled (default true) configuration, the leader broker checks if any bundle’s load is beyond LoadBalancerNamespaceBundle thresholds.
如果启用了 loadBalancerAutoBundleSplitEnabled(默认为 true),则启用自动拆分 Bundle 功能,Leader Broker 会判断是否有 Bundle 的负载超过 LoadBalancerNamespaceBundle 配置的阈值。
1 2 3 4 5 6 | |
If the number of bundles in the namespace is already larger than or equal to MaximumBundles, it skips the split logic.
如果命名空间中的 Bundle 个数已经达到或超过 MaximumBundles,则会跳过拆分逻辑。
Section 3: Computing bundle split boundaries - 第三步:计算 Bundle 拆分边界
Split operations compute the target bundle’s range boundaries to split. The bundle split boundary algorithm is configurable by supportedNamespaceBundleSplitAlgorithms.If we have two bundle ranges in a namespace with range partitions (0x0000, 0X8000, 0xFFFF), and we are currently targeting the first bundle range (0x0000, 0x8000) to split:
接下来计算目标 Bundle 的拆分边界。Bundle 拆分边界算法可通过 supportedNamespaceBundleSplitAlgorithms 配置。假设某个命名空间有两个 Bundle 范围,范围分布是 (0x0000, 0X8000, 0xFFFF),现在要拆分第一个 Bundle 范围 (0x0000, 0x8000),可使用如下拆分算法:
RANGE_EQUALLY_DIVIDE_NAME (default): This algorithm divides the bundle into two parts with the same hash range size, for example target bundle to split=(0x0000, 0x8000) => bundle split boundary=[0x4000].
RANGE_EQUALLY_DIVIDE_NAME(默认算法):该算法将目标 Bundle 拆分为具有相同哈希范围大小的两个部分,例如要拆分的目标 Bundle 为 (0x0000, 0x8000),则拆分边界为 [0x4000]。
TOPIC_COUNT_EQUALLY_DIVIDE: It divides the bundle into two parts with the same topic count. Let’s say there are 6 topics in the target bundle [0x0000, 0x8000):hash(topic1) = 0x0000hash(topic2) = 0x0005hash(topic3) = 0x0010hash(topic4) = 0x0015hash(topic5) = 0x0020hash(topic6) = 0x0025Here we want to split at 0x0012 to make the left and right sides of the number of topics the same. E.g. target bundle to split [0x0000, 0x8000) => bundle split boundary=[0x0012].
TOPIC_COUNT_EQUALLY_DIVIDE:该算法将目标 Bundle 拆分为具有相同主题数的两个部分。假设在目标 Bundle [0x0000, 0x8000) 中有 6 个主题:hash(topic1) = 0x0000hash(topic2) = 0x0005hash(topic3) = 0x0010hash(topic4) = 0x0015hash(topic5) = 0x0020hash(topic6) = 0x0025这种情况会在 0x0012 处进行拆分,使左右两边的主题数相同。如果要拆分的目标 Bundle 为 [0x0000, 0x8000),则拆分边界为 [0x0012]。
Section 4: Splitting bundles by boundaries - 第四步:根据边界拆分 Bundle
Example:Given bundle partitions [0x0000, 0x8000, 0xFFFF], splitBoundaries: [0x4000]Bundle partitions after split = [0x0000, 0x4000, 0x8000, 0xFFFF]Bundles ranges after split = [[0x0000, 0x4000),[0x4000, 0x8000), [0x8000, 0xFFFF]]
示例:给定 Bundle 分区为 [0x0000, 0x8000, 0xFFFF],拆分边界为 [0x4000]。拆分后的 Bundle 分布为 [0x0000, 0x4000, 0x8000, 0xFFFF]。拆分后的 Bundle 范围为 [[0x0000, 0x4000), [0x4000, 0x8000), [0x8000, 0xFFFF]]。
Shedding (unloading) bundles from overloaded brokers - 从过载的 Broker 中缩减(卸载)Bundle
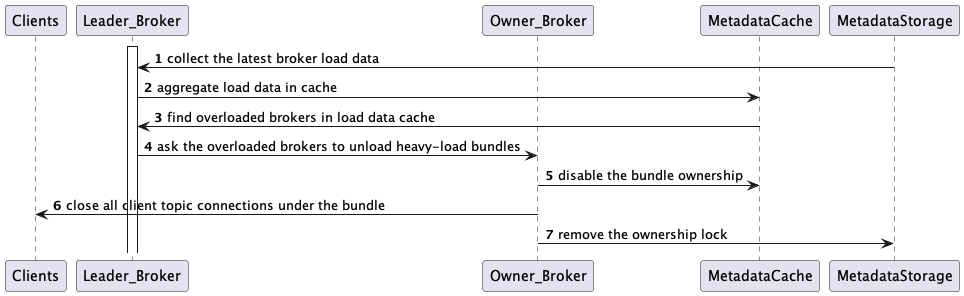
Leader Broker 根据从所有 Broker 中收集的负载信息,识别出哪些 Broker 已经过载,并触发 Bundle 卸载操作,目的是为了重平衡整个集群的流量。
Using the default ThresholdShedder strategy, the leader broker computes the average of the maximal resource usage among CPU, memory, and network IO. After that, the leader finds brokers whose load is higher than the average-based threshold, as shown in Section 5 below. If identified, the leader asks the overloaded brokers to unload some bundles of topics, starting from the high throughput ones, enough to bring the broker load to below the critical threshold.For the unloading request, the owner broker removes the target bundles’ ownerships in the metadata store and closes the client topic connections. Then the clients reinitiate the broker discovery mechanism. Eventually, the leader assigns less-loaded brokers to the unloaded bundles and the clients connect to them.
Leader Broker 默认使用 ThresholdShedder 策略,计算 CPU、内存以及网络 IO 之间最大资源使用率的平均值。之后,Leader 找到那些负载高于此基于平均值阈值的 Broker(见第五步)。找到过载的 Broker 之后,Leader 要求它们从高吞吐量的主题开始卸载一些主题 Bundle,直至将 Broker 负载降低到临界阈值以下。收到卸载请求后,Owner Broker 从 Metadata Store 中移除目标 Bundle 的归属信息,并关闭客户端的主题连接。然后客户端重新启动 Broker 发现机制。最终,Leader 将负载较少的 Broker 分配给被卸载的 Bundle,客户端则连接到新的 Broker。
Section 5: ThresholdShedder: finding overloaded brokers - 第五步:ThresholdShedder:查找过载的 Broker
It first computes the average resource usage of all brokers using the following formula.
ThresholdShedder 首先使用如下公式计算出所有 Broker 的平均资源使用率。
1 2 3 4 5 6 7 8 9 10 11 | |
If any broker’s usage is bigger than avgUsage + y, it is considered an overloaded broker.
- The resource usage “Weight” is by default 1.0 and configurable by
loadBalancerResourceWeightconfigurations. - The historical usage multiplier x is configurable by
loadBalancerHistoryResourcePercentage. By default, it is 0.9, which weighs the previous usage more than the latest. - The
avgUsagebuffer y is configurable byloadBalancerBrokerThresholdShedderPercentage, which is 10% by default.
如果 Broker 的资源使用率大于 avgUsage + y,则被认为过载。
- 资源使用率的权重(Weight)默认为 1.0,可通过
loadBalancerResourceWeight进行配置。 - 历史使用率乘子 x 可通过
loadBalancerHistoryResourcePercentage进行配置。其默认值是 0.9,历史使用率比最近使用率的权重更大。 avgUsage缓冲值 y 可通过loadBalancerBrokerThresholdShedderPercentage进行配置,默认值是 10%。
Takeaways - 总结
In this blog, we reviewed the Pulsar broker load balance logic focusing on its sequence. Here are the broker load balance behaviors that I found important in this review.
- Pulsar groups topics into bundles for easier tracking, and it dynamically assigns and balances the bundles among brokers. If specific bundles are overloaded, they get automatically split to maintain the assignment units to a reasonable level of traffic.
- Pulsar collects the global broker (cpu, memory, network usage) and bundle load data (msg in/out rate) to the leader broker in order to run the algorithmic load balance logic: bundle-broker assignment, bundle splitting, and unloading (shedding).
- The bundle-broker assignment logic randomly selects the least loaded brokers and redirects clients to the assigned brokers’ URLs. The broker-bundle ownerships create ephemeral locks in the metadata store, which are automatically released if the owners become unavailable (lose ownership).
- The bundle-split logic finds target bundles based on the LoadBalancerNamespaceBundle* configuration thresholds, and by default, the bundle ranges are split evenly. After splits, by default, the owner automatically unloads the newly split bundles.
- The auto bundle-unload logic uses the default LoadSheddingStrategy, which finds overloaded brokers based on the average of the max resource usage among CPU, Memory, and Network IO. Then, the leader asks the overloaded brokers to unload some high loaded bundles of topics. Clients’ topic connections under the unloading bundles experience connection close and re-initiate the bundle-broker assignment.
在本博文中,我们回顾了 Pulsar Broker 的负载均衡逻辑,重点关注其时序图。我认为 Broker 负载均衡行为有如下几个要点。
- Pulsar 通过 Bundle 将主题分组以便于跟踪,并在 Broker 之间动态地分配和平衡 Bundle。如果特定的 Bundle 发生过载,则自动进行拆分,将分配单元维护在合理的流量水平。
- Pulsar 将 Broker 全局负载数据(CPU、内存以及网络使用率)以及 Bundle 负载数据(消息输入/输出速率)收集到 Leader Broker,以运行负载均衡算法逻辑:执行 Bundle-Broker 分配、Bundle 拆分和卸载(缩减)。
- Bundle-Broker 分配逻辑随机选择负载最少的 Broker,并将客户端重定向到分配的 Broker URL。Broker-Bundle 归属关系会在 Metadata Store 中创建临时锁,如果 Owner 不可用(失去归属权)则会自动释放锁。
- Bundle 拆分逻辑根据 LoadBalancerNamespaceBundle* 配置的阈值查找目标 Bundle,默认情况下 Bundle 范围被平均拆分。拆分后,Owner 默认自动卸载新拆分的 Bundle。
- Bundle 自动卸载逻辑默认使用 LoadSheddingStrategy,根据 CPU、内存以及网络 IO 的最大资源使用率平均值来查找过载的 Broker。然后 Leader 要求过载的 Broker 卸载一些高负载的主题 Bundle。被卸载的 Bundle 对应的客户端主题连接会被关闭,并重新发起 Bundle-Broker 分配。