String#substring()在Java6和Java7中的实现是不一样的。这是因为Java6的实现可能导致内存问题,所以Java7中为了改善这个问题修改了实现方式。那么Java7中的实现就真的合理吗?
首先让我们来猜测一下,Java是如何实现substring功能的。由于String是不可变的,可能我们会猜测实现机制如下图:
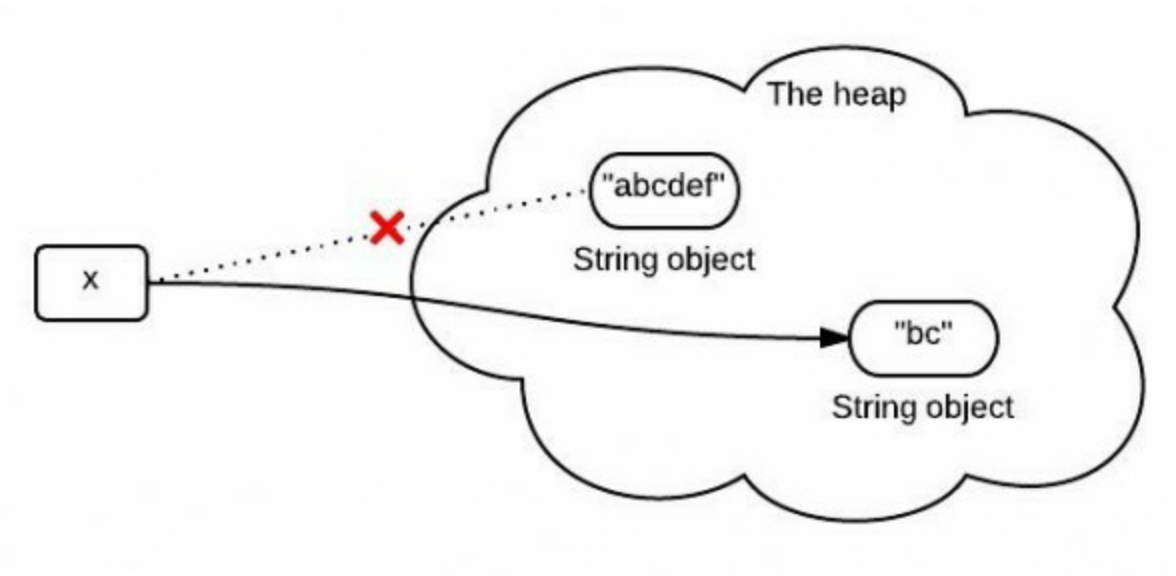
然而,这个图并不完全正确,或者说并没有完全表示出Java堆中真正发生的事情。
Java6中的substring()
Java中字符串是通过字符数组来支持实现的,在JDK6中,String类包含3个实例变量:
- char[] value 表示真实的字符数组;
- int offset 表示数组的偏移量;
- int count 表示String所包含的字符的个数。
当调用substring()方法时,会创建一个新的字符串对象,但是这个字符串的值在java堆中仍然指向的是同一个数组,这两个字符串的不同之处只是他们的count和offset的值。
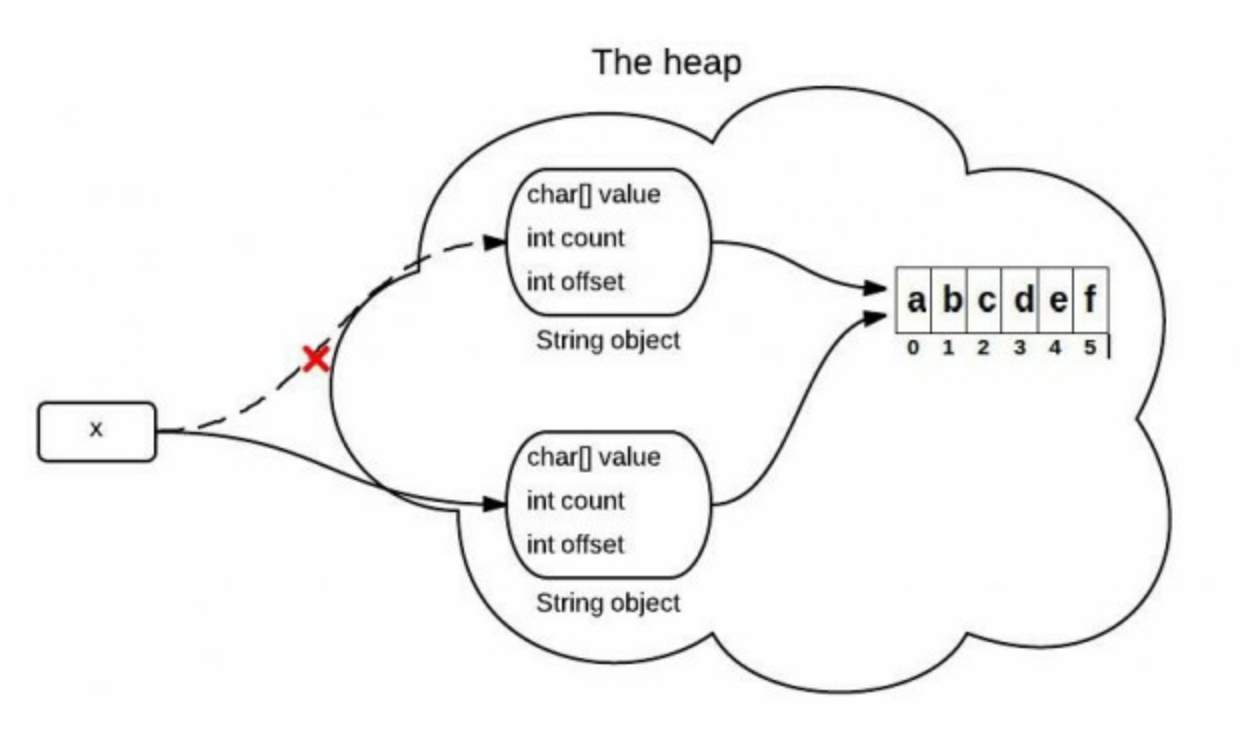
可以参考Java6中的源代码:
1 2 3 4 5 6 7 8 9 10 11 | |
Java6中substring()可能导致的问题
这么实现有一个问题:如果你有一个非常长的字符串,但是你仅仅只需要这个字符串的一小部分,你需要的只是很小的部分,而这个子字符串却要包含整个字符数组。这可能导致内存溢出问题。
我们可以用一个办法来规避这个问题:为substring()得到的子字符串重新创建一个对象。例如:
1
| |
或者:
1
| |
Java7中的substring()
Java7中对上述问题做了修正,当调用substring()方法时,在堆中真正的创建了一个新的数组,当原字符数组没有被引用后就被GC回收了。
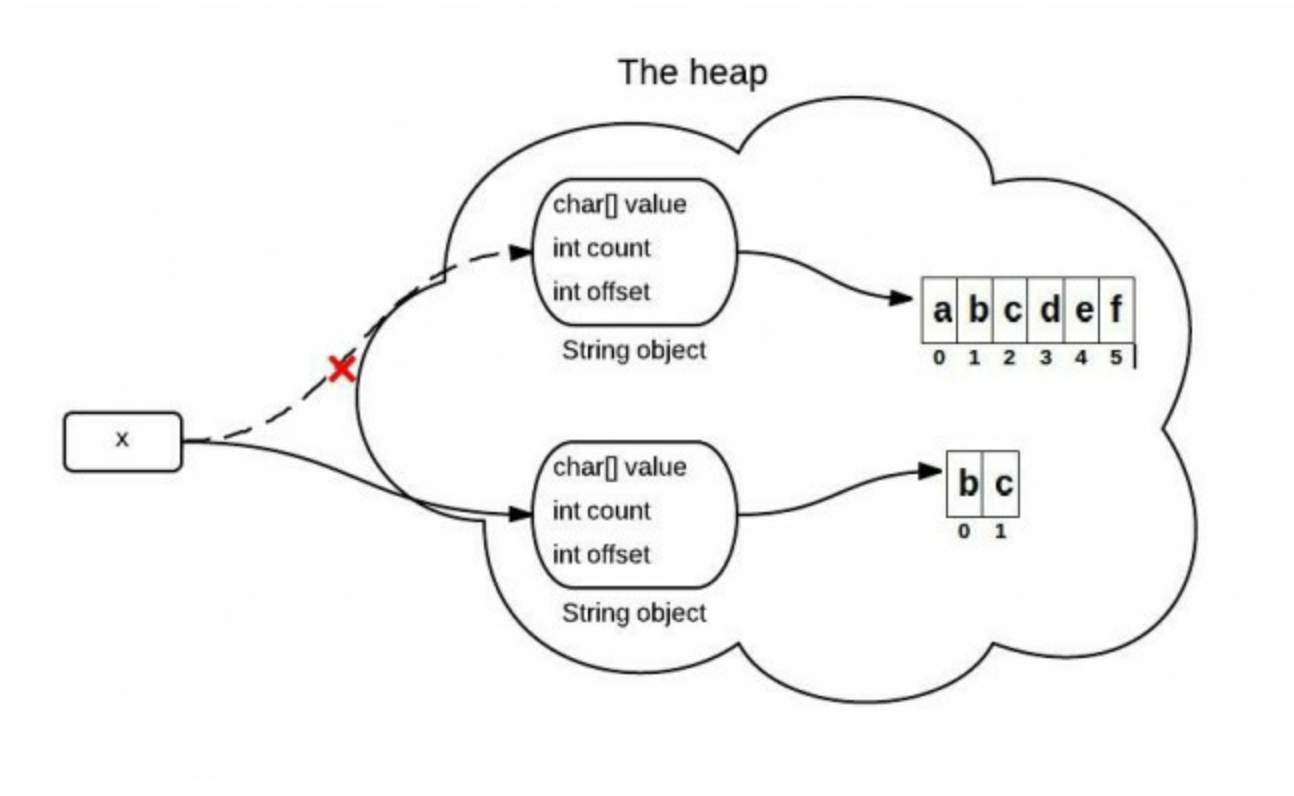
我们看源码:
1 2 3 4 5 6 7 8 9 | |
可以看到Java7通过Arrays.copyOfRange重新创建了一个字符数组。
Java7的修改合理吗?
Java7虽然规避了substring可能出现的内存问题,但是新的实现真的好吗?
Java6的实现,当进行substring时,使用共享内容字符数组,速度会更快,不用重新申请内存。虽然有可能出现本文中的内存性能问题,但也是有方法可以解决的。
而Java7的实现,对任何String,即便不是Large String,都会重新申请内存,速度也会更慢,性能会更差。如果我们程序中处理的大部分都不是Large String的话,这种对性能的影响是不是得不偿失?
如果保持Java6的实现,在处理非Large String时,我们直接调用substring即可;而对Large String则用上文提到的规避方法来解决。
List#sublist()的实现为什么没改变?
Java中有一个和String#substring有着类似逻辑、功能、实现机制的方法:List#sublist。Java6 处理Large List的sublist时,也会出现内存问题;而奇怪的时Java7并未对这个实现进行修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
所以我们在处理Large List时还是需要用规避方法:
1 2 3 | |
为什么Java7不对List#sublist做修改,以让它和String#substring的实现机制继续保持一致呢?不得而知。
Reference
http://www.programcreek.com/2013/09/the-substring-method-in-jdk-6-and-jdk-7/