本文可能是全网最好的对比 Kafka 与 Pulsar 的文章之一。
Apache Kafka 是一种广泛使用的发布订阅(pub-sub)消息系统,起源于 LinkedIn,并于 2011 年成为 Apache 软件基金会(ASF)项目。而近年来,Apache Pulsar 逐渐成为 Kafka 的重要替代品,原本被 Kafka 占据的使用场景正越来越多地转向 Pulsar。在本报告中,我们将回顾 Kafka 与 Pulsar 之间的主要区别,并深入了解 Pulsar 为何势头如此强劲。
本文可能是全网最好的对比 Kafka 与 Pulsar 的文章之一。
Apache Kafka 是一种广泛使用的发布订阅(pub-sub)消息系统,起源于 LinkedIn,并于 2011 年成为 Apache 软件基金会(ASF)项目。而近年来,Apache Pulsar 逐渐成为 Kafka 的重要替代品,原本被 Kafka 占据的使用场景正越来越多地转向 Pulsar。在本报告中,我们将回顾 Kafka 与 Pulsar 之间的主要区别,并深入了解 Pulsar 为何势头如此强劲。
本文翻译自 StreamNative 博客《Achieving Broker Load Balancing with Apache Pulsar》 - 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/p9nWE_cyzYENNxEzXGXcew
In this blog, we talk about the importance of load balancing in distributed computing systems and provide a deep dive on how Pulsar handles broker load balancing. First, we’ll cover Pulsar’s topic-bundle grouping, bundle-broker ownership, and load data models. Then, we’ll walk through Pulsar’s load balancing logic with sequence diagrams that demonstrate bundle assignment, split, and shedding. By the end of this blog, you’ll understand how Pulsar dynamically balances brokers.
本文将探讨负载均衡在分布式计算系统中的重要性,并深入分析 Pulsar 处理 Broker 负载均衡的方式。首先我们介绍 Pulsar 中的 Topic-Bundle 分组、Bundle-Broker 归属关系以及负载数据模型。然后讲解 Pulsar 的负载均衡逻辑,通过时序图来展示 Bundle 的分配、拆分和缩减过程。通过本文,你将了解 Pulsar Broker 是如何做到动态均衡的。
Before we dive into the details of Pulsar’s broker load balancing, we’ll briefly discuss the challenges of distributed computing, and specifically, systems with monolithic architectures.
在深入探讨 Pulsar Broker 负载均衡的细节之前,我们先简要讨论分布式计算的挑战,特别是单体架构系统的挑战。
本文翻译自 StreamNative 博客《What the FLiP is the FLiP Stack?》
- 原文链接:https://streamnative.io/blog/engineering/2022-04-14-what-the-flip-is-the-flip-stack/
- 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/KoigahiZ2sTG-GhD2fG0Fw
In this article on the FLiP Stack, we will explain how to build a real-time event driven application using the latest open source frameworks. We will walk through building a Python IoT application utilizing Apache Pulsar, Apache Flink, Apache Spark, and Apache NiFi. You will see how quickly we can build applications for a plethora of use cases. The easy, fast, scalable way: The FLiP Way.
本文将介绍 FLiP 技术栈,我们将解释如何使用最新的开源框架构建实时事件驱动应用程序,并介绍如何通过 Apache Pulsar、Apache Flink、Apache Spark 和 Apache NiFi 构建一个 Python IoT 应用。得益于 FLiP 的简单、快速、可扩展的特性,使用 FLiP 可以快速地为各种场景构建应用程序。
The FLiP Stack is a number of open source technologies that work well together. FLiP is a best practice pattern for building a variety of streaming data applications. The projects in the stack are dictated by the needs of that use case; the available technologies in the builder’s current stack; and the desired end results. As we shall see, there are several variations of the FLiP stack built upon the base of Apache Flink and Apache Pulsar.
FLiP 技术栈由许多可协同工作的开源技术组成,是构建各种流数据应用程序的最佳实践模式。FLiP 技术栈包含哪些项目并不是固定的,而是由特定场景的需求、团队当前掌握的技术栈、以及期望的最终结果决定。建立在 Apache Flink 和 Apache Pulsar 基础上的 FLiP 技术栈有很多变体。
本文翻译自 《Apache BookKeeper Insights Part 1 — External Consensus and Dynamic Membership》,作者 Jack Vanlightly
- 原文链接:https://medium.com/splunk-maas/apache-bookkeeper-insights-part-1-external-consensus-and-dynamic-membership-c259f388da21
- 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/i2CzmL8k2EKbjxNlW0OG6w
The BookKeeper replication protocol is pretty interesting, it’s quite different to other replication protocols that people are used to in the messaging space such as Raft (RabbitMQ Quorum Queues, Red Panda, NATS Streaming) or the Apache Kafka replication protocol. But being different means that people often don’t understand it fully and can either get tripped up when it behaves in a way they don’t expect or not use it to its full potential.
BookKeeper 复制协议非常有趣,它与人们在消息领域习惯使用的其他复制协议大不相同,例如 RabbitMQ Quorum Queues、Red Panda 及 NATS Streaming 使用的 Raft 协议和 Apache Kafka 使用的复制协议。但与众不同意味着人们往往无法完全掌握 BookKeeper 的各项玩法,例如当 BookKeeper 的运行方式不符合预期时不知如何解决,又或是没能充分利用 BookKeeper 的各项优势功能。
This series aims to help people understand some fundamental insights into what makes BookKeeper different and also dig into some of the nuances of the protocol. We’ll dig into the “why” the protocol is the way it is and also some of the ramifications of those design decisions.
本系列文章旨在帮助大家了解那些使 BookKeeper 与众不同的一些基本见解,详细分析该协议的一些细微差别。我们将深入研究 BookKeeper 复制协议背后的设计考量,以及这些设计决策所带来的结果。
本文译自 StreamNatvie 官方发布的《2022 Pulsar 性能测试报告》
As we move into 2022, the Apache PulsarTM versus Apache KafkaⓇ debate continues. Organizations often make comparisons based on features, capabilities, size of the community, and a number of other metrics of varying importance. This report focuses purely on comparing the technical performance based on benchmark tests.
进入 2022 年,人们对 Apache PulsarTM 与 Apache KafkaⓇ 的争论仍在持续。大家通常会对比二者的特性、能力、社区规模以及其他一系列重要性各异的指标。本报告则侧重于基于基准测试对比二者的技术性能。
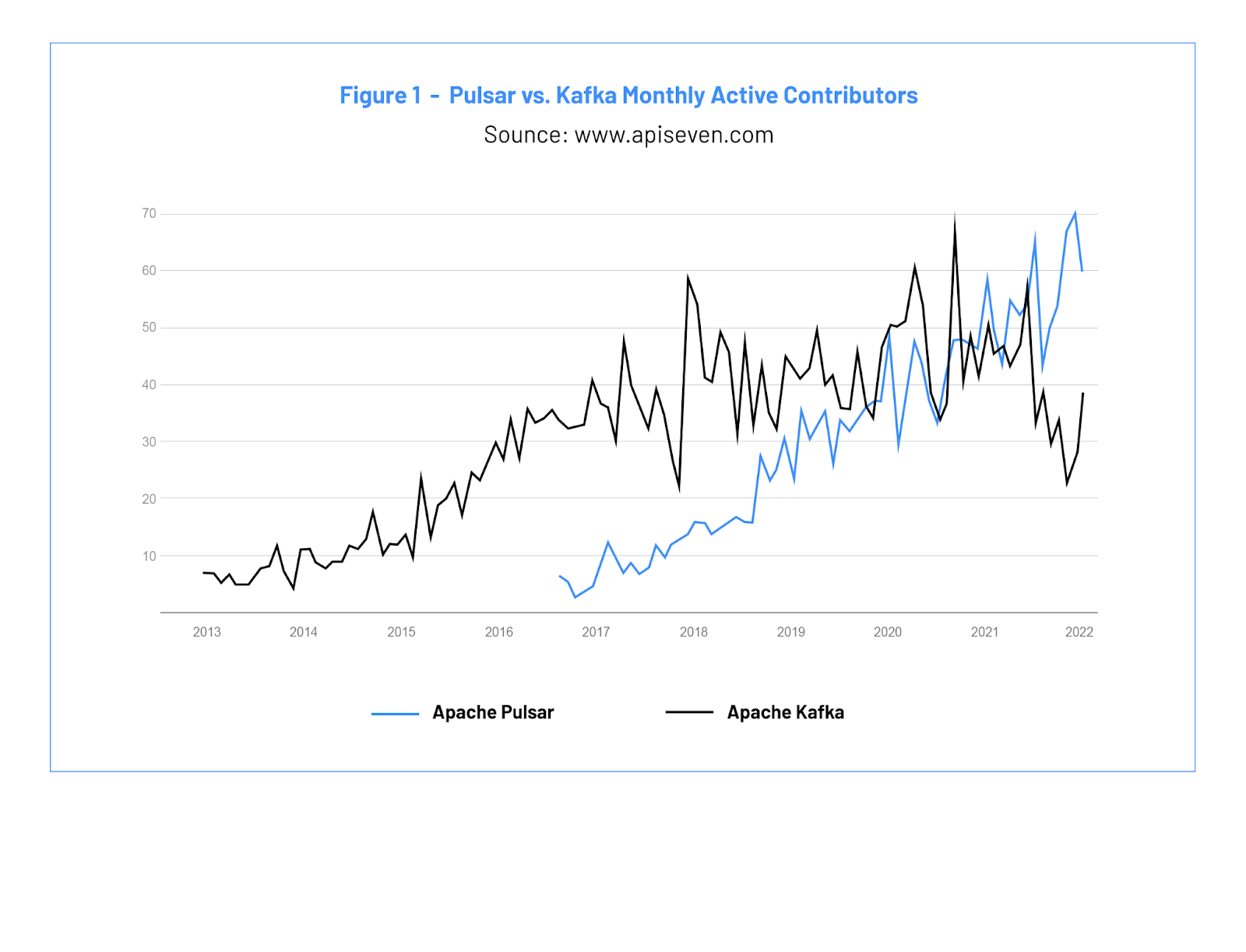
The last widely published Pulsar versus Kafka benchmark was performed in 2020, and a lot has happened since then. In 2021, Pulsar ranked as a Top 5 Apache Software Foundation project and surpassed Apache Kafka in monthly active contributors as shown in the chart below. Pulsar also averaged more monthly active contributors than Kafka for most of the past 18 months.
上一次广泛发布的 Pulsar 与 Kafka 基准测试是在 2020 年进行的,而此后发生了很多事情。2021 年,Pulsar 被评为 [Apache 软件基金会 Top 5 活跃提交项目],并在月度活跃贡献者数目上力压 Apache Kafka,如下图所示。在过去 18 个月中,大部分时间 Pulsar 的平均月度活跃贡献者都超越了 Kafka。
本文翻译自《Offset Implementation in Kafka-on-Pulsar》
- 译文发表于 Apache Pulsar 公众号:https://mp.weixin.qq.com/s/JXLquQkJFAzu8uw_lJaIcg
Protocol handlers were introduced in Pulsar 2.5.0 (released in January 2020) to extend Pulsar’s capabilities to other messaging domains. By default, Pulsar brokers only support Pulsar protocol. With protocol handlers, Pulsar brokers can support other messaging protocols, including Kafka, AMQP, and MQTT. This allows Pulsar to interact with applications built on other messaging technologies, expanding the Pulsar ecosystem.
协议处理器 是 2020 年一月份发布的 Pulsar 2.5.0 所引入的新功能,目的是将 Pulsar 的能力扩展到其他消息领域。默认情况下 Pulsar Broker 仅支持 Pulsar 协议。而通过协议处理器,Pulsar Broker 就可以支持其他消息协议,包括 Kafka、AMQP 以及 MQTT(现已新增 RocketMQ)。这使得 Pulsar 可以与基于其他消息技术的应用进行交互,从而扩展 Pulsar 生态系统。
Kafka-on-Pulsar (KoP) is a protocol handler that brings native Kafka protocol into Pulsar. It enables developers to publish data into or fetch data from Pulsar using existing Kafka applications without code change. KoP significantly lowers the barrier to Pulsar adoption for Kafka users, making it one of the most popular protocol handlers.
Kafka-on-Pulsar (KoP) 就是一种协议处理协议,它将原生 Kafka 协议引入了 Pulsar,使得开发人员能够使用现有的 Kafka 应用将数据发布到 Pulsar 或从 Pulsar 读取数据,而无需更改代码。KoP 极大降低了 Kafka 用户使用 Pulsar 的壁垒,这让 KoP 成为最受欢迎的协议处理器之一。
Resilience4j is a widely-used library which inspired by Hystrix, it helps with building fault tolerance distributed systems. We are using its circuit breakder module to prevent a cascade of failures when a remote service is down.
You can implement a circuit break based on the official manual, and you may want to verify if it works well or not after . Here’re some tips
2019年在大团队内部组织了一个 Study Group,主要目的是一起学习、一起分享、一起成长;上个季度我们的一项重点是完成了《Clean Code》这本书的拆解和分享,本文是对其中最后一章的一个总结。其实最后一章是对全书的总结,随意本文也可以近似看成是对全书的总结吧。
原始总结请参考 https://github.com/AlphaWang/alpha-book-clean-code/tree/master/17_smells_heuristics
最近梳理了下 Redis 知识图谱,画了个脑图,涵盖了 Redis 数据类型、持久化机制、主从、哨兵、集群、应用及运维;具体见下图:
最近在研究分布式链路跟踪系统,Google Dapper 当然是必读的论文了,目前网上能搜到一些中文翻译版,然而读下来个人感觉略生硬;这里试着在前人的肩膀上重新翻译一遍这个论文,权当是个人的学习笔记,如果同时能给其他人带来好处那就更好了。
同时把译文放到了 github,如您发现翻译错误或者不通顺之处,恳请提交 github PR: https://github.com/AlphaWang/alpha-dapper-translation
现代互联网服务通常都是复杂的大规模分布式系统。这些系统由多个软件模块构成,这些软件模块可能由不同的团队开发、可能使用不同的编程语言实现、可能布在横跨多个数据中心的几千台服务器上。这种环境下就急需能帮助理解系统行为、能用于分析性能问题的工具。
本文将介绍 Dapper 这个在 Google 生产环境下的分布式系统跟踪服务的设计,并阐述它是如何满足在一个超大规模系统上达到低损耗(low overhead)、应用级透明(application-level transparency)、大范围部署(ubiquitous deployment)这三个需求的。Dapper 与其他一些跟踪系统的概念类似,尤其是 Magpie[3] 和X-Trace[12],但是我们进行了一些特定的设计,使得 Dapper 能成功应用在我们的环境上,例如我们使用了采样并将性能测量(instrumentation)限制在很小一部分公用库里。